
fastTextで自然言語(日本語)の学習モデルを生成する手順まとめ
- 公開日:2018/11/03
- 更新日:2020/10/07
- 投稿者:n bit
Facebookが開発したfastTextを利用して自然言語(Wikipediaの日本語全記事)の機械学習モデルを生成するまでの手順を解説。また生成した学習モデルを使って類語抽出や単語ベクトルの足し算引き算等の演算テストを行う方法までコード付きで紹介します。
この記事は約 分で読めます。(文字)
fastTextで日本語を機械学習させる手順
Facebook発表の『fastText』利用して日本語の機械学習モデルを生成する手順を解説していきます。
Wikipediaの全記事のダンプデータ取得
学習本の文章にはWikipediaを利用します。下記URLから、最新のWikipedia全記事ダンプデータをダウンロードしましょう。取得データはXML形式の圧縮ファイルになっています。
任意のディレクトリに保存してください。
Wikipediaのダンプデータから文章のみを抽出
WikiExtractorを使用してXMLから文章のみを抽出します。WikiExtractorは、Wikipediaデータベースのダンプデータから文章を抽出するPythonスクリプトです。
cdコマンドで任意のディレクトリに移動してGitからcloneします。
$ cd 任意のインストール先ディレクトリ
$ git clone https://github.com/attardi/wikiextractor.git
出力結果
Cloning into 'wikiextractor'...
remote: Enumerating objects: 523, done.
remote: Total 523 (delta 0), reused 0 (delta 0), pack-reused 523
Receiving objects: 100% (523/523), 454.22 KiB | 366.00 KiB/s, done.
Resolving deltas: 100% (297/297), done.
スクリプトは直接起動することもできますので下記コマンドを実行して直接処理を行います。
- python wikiextractor/WikiExtractor.py -b 500M -o [出力先ディレクトリ] [ダンプデータ]
$ python wikiextractor/WikiExtractor.py -b 500M -o wikiextractor_output/corpus jawiki_dump/jawiki-20181020-pages-articles-multistream.xml.bz2
出力結果
・
・
・
INFO: Finished 11-process extraction of 1125721 articles in 4737.9s (237.6 art/s)
結構処理が重たいのか処理中ファンが全開で回っています。処理完了までに80分程度かかりました。
ダンプデータとWikiExtractorを使って文章抽出した後のデータを比較すると以下のようになります。
元データ

WikiExtractor実行後のデータ
出力先ディレクトリに指定したwikiextractor_output/corpus/AAディレクトリ内に連番ファイルが複数生成されます。今回は6つのファイルが生成されました。
- wiki_00:524.2MB
- wiki_01:524.2MB
- wiki_02:524.2MB
- wiki_03:524.2MB
- wiki_04:524.2MB
- wiki_05:175.3MB
複数生成された連番ファイルをcatコマンドで1つのファイルに結合しておきます。
$ cd /Users/xx/wikiextractor_output/corpus/AA
$ cat wiki_00 wiki_01 wiki_02 wiki_03 wiki_04 wiki_05 >wiki_20181020
合計で約2.7GBの『wiki_20181020』ファイルが作成されました。
文章のみ抽出したデータを分かち書き
文章として連なったままのテキストデータではベクトルの計算を行うことができませんので事前に分かち書きを行っておきましょう。MeCabと新語辞書mecab-ipadic-NEologdを使用して文章のみ抽出したデータを分かち書きします。
MeCabと新語辞書mecab-ipadic-NEologdの環境構築がまだ完了していない方は下記のページを参考にしてインストールしておいてください。

Python+MeCab+NEologdで自然言語の形態素解析環境構築方法
Python、MeCab、mecab-ipadic-NEologdで自然言語の機械学習等を行う最初の工程「形態素解析(分かち書きや品詞等の推定)」用の環境構築方法について解説。辞書ファイルにmecab-ipadic-NEologdを利用しますので新しい言葉にも対応した形態素解析を行えます。
分かち書きを実行するには下記のコマンドを入力してください。
- mecab -O wakati -d [辞書ディレクトリ] [対象テキストファイル] -o [出力先ファイル]
$ mecab -O wakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd wiki_20181020 -o wiki_wakati_20181020
そのまま実行するとバッファサイズが足りないとエラーが出ました。
- input-buffer overflow. The line is split. use -b #SIZE option.
仕方ないのでバッファサイズを指定するオプションを使って対応しておきましょう。今回は適正値を探すのが大変なのでいきなり上限まで(最大8192 * 640)引き上げて指定します。
オプションを使った実行には下記のコマンドを入力してください。
$ mecab -O wakati -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd -b 5242880 wiki_20181020 -o wiki_wakati_20181020
今度はエラーが出ず無事に分かち書きできました。分かち書きの実行処理はわりと早く20分程度で完了です。さすがMeCab!
今回指定したMeCabのオプションコマンド
今回実行時に指定したMeCabのオプションコマンドについて下記にまとめておきます。
| オプション | フルコマンド | 指定値 | 説明 |
|---|---|---|---|
| -O | --output-format-type | TYPE | 出力フォーマットの形式を指定 ・dump ・wakati |
| -b | --input-buffer-size | INT | 入力文字列のバッファサイズを指定 ・最大8192 * 640の値まで |
| -d | --dicdir | DIR | 使用する辞書を指定 |
| -o | --output | FILE | 出力先ファイルを指定 |
分かち書きデータからfastTextで機械学習する
『fastText』はFacebookが開発した自然言語の機械学習ツールです。Googleが開発したWord2Vecよりも学習速度が高速で精度も高いので多く利用されています。
fastTextのインストール
任意のディレクトリにcdコマンドで移動してfastTextをGitからcloneします。
$ cd 任意のインストール先ディレクトリ
$ git clone https://github.com/facebookresearch/fastText.git
出力結果
Cloning into 'fastText'...
remote: Enumerating objects: 1, done.
remote: Counting objects: 100% (1/1), done.
remote: Total 2629 (delta 0), reused 0 (delta 0), pack-reused 2628
Receiving objects: 100% (2629/2629), 7.63 MiB | 476.00 KiB/s, done.
Resolving deltas: 100% (1637/1637), done.
『make』コマンドで自動的にコンパイルします。
$ cd fastText
$ make
出力結果
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops -c src/args.cc
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops -c src/dictionary.cc
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops -c src/productquantizer.cc
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops -c src/matrix.cc
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops -c src/qmatrix.cc
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops -c src/vector.cc
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops -c src/model.cc
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops -c src/utils.cc
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops -c src/fasttext.cc
c++ -pthread -std=c++0x -march=native -O3 -funroll-loops args.o dictionary.o productquantizer.o matrix.o qmatrix.o vector.o model.o utils.o fasttext.o src/main.cc -o fasttext
fastTextで機械学習する
MeCabと新語辞書mecab-ipadic-NEologdを使用して分かち書きしたWikipediaの文章のみ抽出データをfastTextで学習させてモデルを生成します。
学習時のベクトル次元数のパラメータはパラメータの目安は以下のように言われています。
- 小規模コーパス(〜50M words):100次元
- 中規模コーパス(〜200M〜 words):200次元
- 大規模コーパス(300M〜 words):300次元
今回はWikipediaの全文を利用して学習しますので大規模コーパスに該当するでしょう。ベクトルの次元数としては300次元を設定します。
- $ ./fasttext skipgram -input [学習対象ファイル] -output model [出力先ファイル] -dim [ベクトルの次元数]
$ ./fasttext skipgram -input ../wikiextractor_output/corpus/AA/wiki_wakati_20181020 -output model_20181020 -dim 300
スタートすると学習対象ファイルの概要が表示されます。
- Read 541M words
- Number of words: 980734
- Number of labels: 0
『Read 541M words』になっていますので300次元でそのまま行きます。
出力結果
Progress: 0.0% words/sec/thread: 504 lr: 0.050000 loss: 4.159913 ETA: 12
Progress: 0.0% words/sec/thread: 2137 lr: 0.049999 loss: 4.155802 ETA: 2
Progress: 0.0% words/sec/thread: 3993 lr: 0.049998 loss: 4.149930 ETA: 1
Progress: 0.0% words/sec/thread: 5677 lr: 0.049997 loss: 4.144916 ETA: 1
Progress: 0.0% words/sec/thread: 7154 lr: 0.049996 loss: 4.139351 ETA:
・
・
・
Progress: 100.0% words/sec/thread: 38567 lr: 0.000002 loss: 0.229509 ETA:
Progress: 100.0% words/sec/thread: 38567 lr: 0.000001 loss: 0.229505 ETA:
Progress: 100.0% words/sec/thread: 38567 lr: -0.000000 loss: 0.229502 ETA:
Progress: 100.0% words/sec/thread: 38567 lr: 0.000000 loss: 0.229502 ETA:
0h 0m
学習の計算が始まると学習時間の目安が表示されます。私の環境では1h37mと表示されました。実行処理中はファンも周りっぱなしで結構負担がかかっていそうですが『iStats』でチェックする限りは心配しすぎるほどでもないと思います。
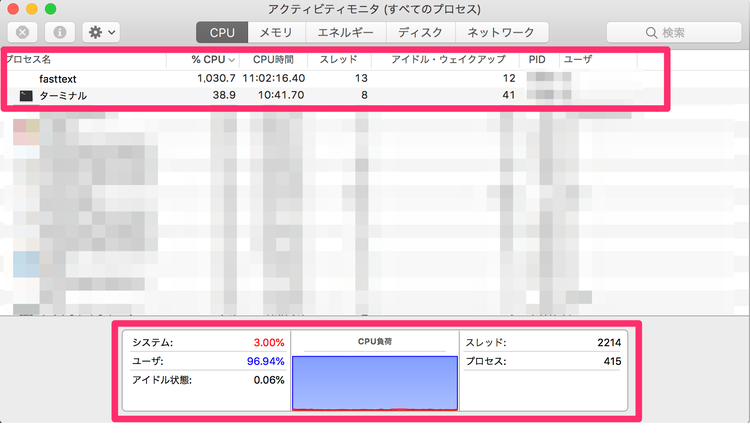
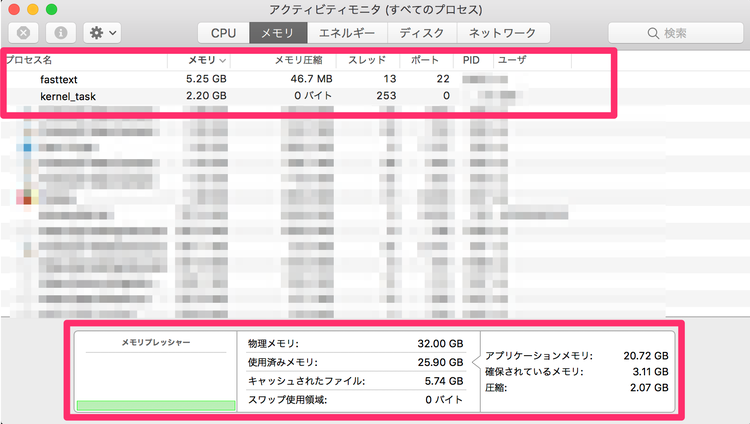
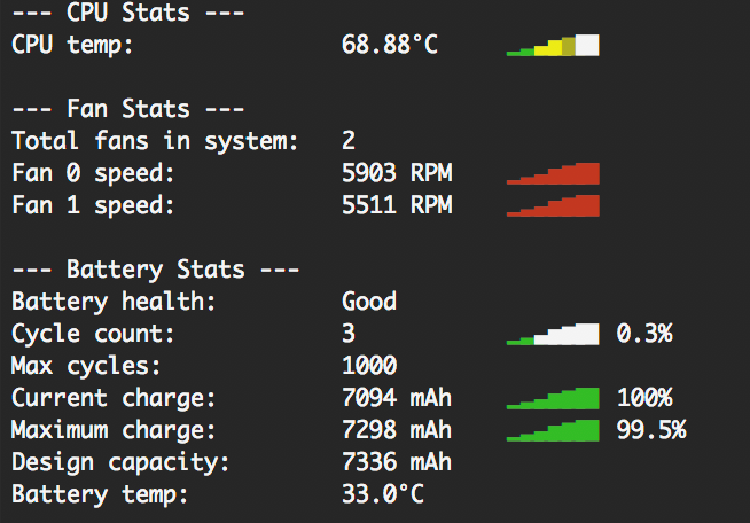
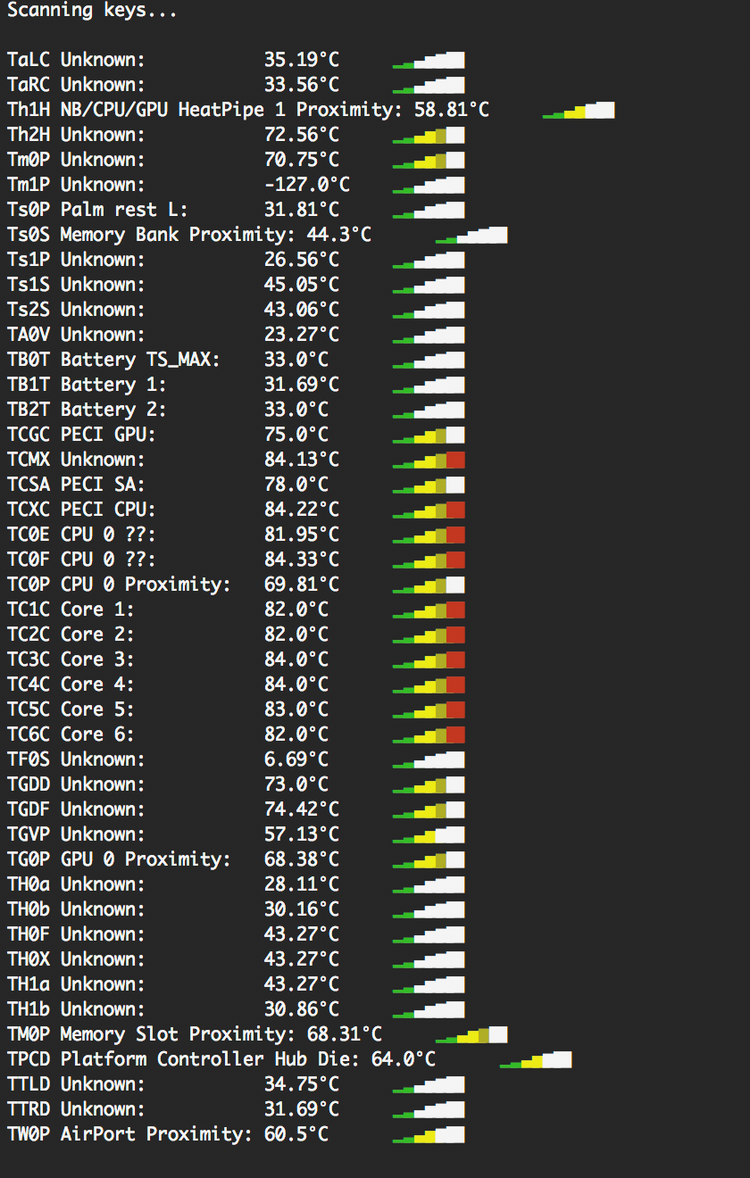
『iStats』を使ったMacBook Proの管理方法は下記のページで解説しています。

Mac Book ProのCPUやシステム温度、ファンスピード等の管理方法
MacBook Proで負荷のかかる処理を行った時にファンが全力で回ります。実際どれぐらいの負荷がかかっていてCPUの温度やその他システムの温度がどのような状態にあるのか、ファンはどれぐらい回っているかなどを数字で客観的に把握し管理する方法を紹介します。
学習の計算が完了すると『model_20181020.vec』と『model_20181020.bin』が出力されます。
バイナリファイルの生成
.vec(model_20181020.vec)はテキストファイルのためモデルのロードにかなりの時間がかかります。バイナリファイルであればインポート時間をかなり高速化することができますので.vecファイルから専用のバイナリファイル(.bin)を生成しておきましょう。
Note
fastTextから自動生成されているバイナリファイル『model_20181020.bin』はエンコード問題が発生したので利用しません。
バイナリファイルに変換するため下記のコードを利用します。
import gensim
# model.vecをload
model = gensim.models.KeyedVectors.load_word2vec_format('model_20181020.vec', binary=False)
# バイナリファイルとして保存
model.save_word2vec_format("fasttext_wiki_20181020.bin", binary=True)
『fasttext_wiki_20181020.bin』が生成されましたらfastTextを使った学習モデルの生成は全て完了です。モデルを使ってテストしてみましょう。
fastTextの機械学習モデルで類語抽出や演算テスト
fastTextの学習モデルを使い類語の抽出や単語の足し引きなどの演算テストをおこないます。テストにはgensimとpprintが必要です。まだインストールが済んでいない方は先にインストール作業を済ませておいてください。
gensimのインストール
$ pip install gensimpprintのインストール
$ pip install pprintgensimのインストール方法は下記のページでも解説しています。

自然言語処理用のPythonモジュール『gensim』のインストール方法
自然言語処理用のモジュールが数多くパッケージ化されたPythonライブラリ『gensim』をPython3の環境にpipコマンドを使ってインストールする方法についての解説です。ベクトル空間の学習モデルを扱うことができます。
類語の抽出テスト
類語抽出のテスト用のコードは以下の通りです。
import gensim
import pprint
model = gensim.models.KeyedVectors.load_word2vec_format('./fastText_output/fasttext_wiki_20181020.bin', binary=True)
pprint.pprint(model.most_similar(positive=['SEO']))
類語の抽出にはmost_similar()関数を使います。most_similar()関数は学習モデル内で引数に渡した単語の単語ベクトルとより近い単語ベクトルをもつ単語を抽出してくれる関数です。
model.most_similar(positive=['類語判定させる単語'])
出力結果
類語判定させる単語に『SEO』を渡して抽出した結果です。
[('検索エンジン最適化', 0.7309184670448303),
('検索エンジンマーケティング', 0.7129291296005249),
('検索連動型広告', 0.673938512802124),
('Webマーケティング', 0.6733667850494385),
('インターネットマーケティング', 0.6725453734397888),
('WEO', 0.6664092540740967),
('サーチエンジンマーケティング', 0.6651182174682617),
('ウェブマーケティング', 0.6629313230514526),
('ブラックハットSEO', 0.6582387089729309),
('NAVERブログ', 0.6567591428756714)]
割と想定される結果が返っていると思います。
足し引きなどの演算テスト
単語ベクトルの足し算引き算の演算にもmost_similar()関数を利用します。テスト用のコードは以下の通りです。
import gensim
import pprint
model = gensim.models.KeyedVectors.load_word2vec_format('./fastText_output/fasttext_wiki_20181020.bin', binary=True)
pprint.pprint(model.most_similar(positive=["人間", "スマホ"]))
pprint.pprint(model.most_similar(positive=["人間"], negative=["感情"]))
単語ベクトルの足し算
単語ベクトルを足す場合はpositiveにリスト形式で渡します。
model.most_similar(positive=['足す単語1', '足す単語2'])
出力結果
『人間+スマホ』で単語ベクトルの足し算を行ってみました。
[('アンドロイドアプリ', 0.6502420902252197),
('ながらスマホ', 0.6464501023292542),
('アプリボワゼ', 0.6255478858947754),
('スマートアバター', 0.6236748695373535),
('千歌音', 0.622641384601593),
('スマートフォン', 0.6216732263565063),
('ネット社会', 0.618942379951477),
('バーチャルペット', 0.6157370805740356),
('ネットナビ', 0.6132873892784119),
('人間並', 0.6074398756027222)]
単語が『スマホ』でもそれなりに演算してくれています。『ながらスマホ』などが結果で返ってきているのが面白いですね。
単語ベクトルの引き算
単語ベクトルの引き算を行う場合はnegativeの中に引きたい単語を渡すことで演算されます。
pprint.pprint(model.most_similar(positive=['足す単語'], negative=['引く単語']))
出力結果
『人間−感情』で単語ベクトルの引き算を行ってみました。
[('生物', 0.33645519614219666),
('小型ロボット', 0.3321981430053711),
('人類', 0.331537127494812),
('生き物', 0.32656198740005493),
('知的生命体', 0.3200429081916809),
('動物', 0.31320303678512573),
('獣', 0.3043139576911926),
('喰う', 0.2999400794506073),
('人間社会', 0.29950663447380066),
('生きもの', 0.29651132225990295)]
何となくイメージしやすい演算結果が返ってきています。『人間社会』と言う結果は少し悲しくなりますが・・・。
今日のdot
上記で紹介した以外にも様々な演算テストを行ってみましたが結論としては学習前のコーパスの前処理をもっとしっかりと行う必要がありそうです。前処理によって学習結果にもたらす影響は大きそうです。
あと『fastText』の計算速度はWord2Vecに比べてかなり早いといえます。前処理を複数パターンテストして機械学習を行っても十分に耐えられる速度と言えるでしょう。
今回の『fastText』を利用した自然言語の機械学習モデル生成手順を元に、前処理を行ったテスト結果もまた後日公開します。
【フリーランス向けの完全無料Pythonプログラミング講座】
dot blogではこの記事以外にも完全無料でフリーランス向けのPythonプログラミング講座を公開中です。フリーランスとして活躍し稼ぐための強力な武器となりますよ。

Python入門講座【無料のプログラミング学習講座】
最近特に注目度が高くなってきているプログラミング言語Python。転職、フリーランス、独立・起業を検討中、日々の業務が忙しい社会人等は今こそ身に付けておきたいスキルの1つ。初心者向けにやさしいプログラミング学習内容のPython入門講座を無料で公開。

