
Python入門|リスト操作の基本をマスター【list型】
- 公開日:2018/05/30
- 更新日:2018/10/19
- 投稿者:n bit
今回はPythonの【list型】リストについて学習していきます。リストの概念や基本的な作成方法、演算子を使ったリスト操作、リスト内の要素の値を取得する方法、リストの入れ子構造のリスト操作、スライス機能、リスト内の値の変更や要素の削除等を解説します。
この記事は約 分で読めます。(文字)
list【リスト】とは
プログラミングにおいてリストを利用することはとても多いです。そもそもリストとは何でしょうか。int型、float型、bool型、str型の変数では1つの要素を扱いました。例えば、int型の変数\(x\)と言うボックスに10と言う数字を代入するといったイメージでしたね。
データ型がlist型の変数の場合は変数内に複数のボックスがあるイメージで、同時に複数の要素を扱うことができます。各ボックスの並びには順序がありインデックス番号が割り振られています。
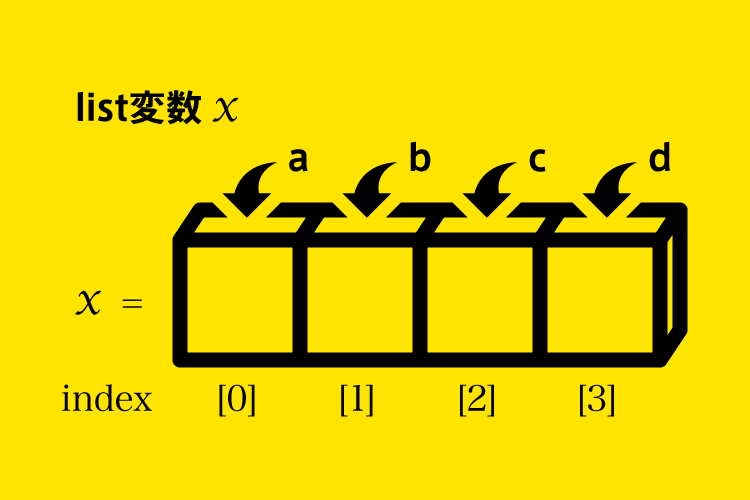
インデックス番号は各ボックスの順序(場所)を示すもので変数内の各要素にアクセスする時などに利用します。
リストの構成やインデックスの役割はコインロッカー等をイメージすると分かりやすいかもしれません。コインロッカー(変数)には決められた順序で並んだ複数のボックスが用意されており、その中には荷物(要素、値)を格納(代入)します。そして各荷物(要素、値)を取得するためにはロッカー番号(インデックス番号)が必要ですよね。
何となくイメージできたでしょうか。後は実際に操作していく中で徐々に理解していきましょう。
【list型】リスト操作の基本
なんとなくリストのイメージをつかんだところでまずは実際に【list型】リストを作成してみましょう。
【list型】リストの作成方法
【list型】リストを作成するためには角括弧【[] 】で全要素を囲み各要素間は【, 】でつなぎます。
x = ['a', 'b', 'c', 'd']
print(type(x))
print(x)
出力結果
<class 'list'>
['a', 'b', 'c', 'd']
データ型がlistになっていることが確認できます。
データ型は混在しても構成できる
リストに格納することができる要素は様々なデータ型が格納できます。また、1つのデータ型に限ることがなく複数のデータ型を混ぜて格納することも可能です。各要素の記述方法はそれぞれのデータ型の記述方法に従います。
例えば、int型、float型、bool型、str型を混在させてリストを作成する場合は下記のようになります。
x = [10, 10.5, False, 'a']
print(type(x))
print(x)
出力結果
<class 'list'>
[10, 10.5, False, 'a']
様々なデータ型を混在させてもデータ型タイプはlistになっていることが確認できます。
もちろん複数の変数を使ってリストを作成することもできます。変数を使ってリストを作成する場合は各変数間を【, 】でつなぎ角括弧【[] 】で全変数を囲むだけです。
a = 'a'
b = 'b'
c = 'c'
d = 'd'
x = [a, b, c, d]
print(x)
出力結果
['a', 'b', 'c', 'd']
リストの中にリストを含むことができる
リストは要素にリストを含むこともできます。直接記述する場合は角括弧【[] 】を入れ子構造にして記述します。
x = [['a', 'b', 'c', 'd'], ['e', 'f', 'g', 'h']]
print(x)
出力結果
[['a', 'b', 'c', 'd'], ['e', 'f', 'g', 'h']]
実際にプログラミングを行う段階では直接記述する事は比較的少ないかと思います。下記のように変数を利用して複数のリストをリスト型に格納するケースが多いでしょう。いずれのやり方でも出力結果は同じです。
x = ['a', 'b', 'c', 'd']
y = ['e', 'f', 'g', 'h']
z = [x, y]
print(z)
出力結果
[['a', 'b', 'c', 'd'], ['e', 'f', 'g', 'h']]
演算子を使った【list型】リストの操作
リストも演算子を使って操作することが可能です。リストで利用することができる演算子は\(+\)と\(*\)の2つです。
リスト操作に利用できる演算子の一覧表
| 演算子 | 演算例 | 演算 |
|---|---|---|
| + | a + b | リストの結合 |
| * | a * n | リストを\(n\)回繰り返し |
演算子を使ったリストの結合
\(+\)演算子を使うことで複数のリストを結合することができます。この辺の操作はstr型の演算子を利用する時と同じですね。
x = ['a', 'b', 'c', 'd']
y = ['e', 'f', 'g', 'h']
z = x + y
print(z)
出力結果
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
複数のリスト要素として格納されるわけではなく各要素が1つのリストとして結合されます。
演算子を使ったリストの繰り返し
\(*\)演算子を利用することでリストを\(n\)回繰り返したリストを作成することができます。
x = ['a', 'b', 'c', 'd']
z = x * 3
print(z)
出力結果
['a', 'b', 'c', 'd', 'a', 'b', 'c', 'd', 'a', 'b', 'c', 'd']
こちらも最終は1つのリストとして結合されていることを確認しておいてください。
演算子の複合利用
\(+\)と\(*\)それぞれの演算子は複合して利用することも可能です。
x = ['a', 'b', 'c', 'd']
y = ['e', 'f', 'g', 'h']
z = x * 2 + y
print(z)
出力結果
['a', 'b', 'c', 'd', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
+=によるリストの追加
リスト方でも\(+=\)を利用することができます。最初にから空リストを作成してから後に追加していきます。
x = []
x += ['a', 'b', 'c', 'd']
x += ['e', 'f', 'g', 'h']
print(x)
出力結果
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
このように演算子を使ったリスト結合はすべて1つのリストとして結合されます。
空リスト
空リストの作成方法は先ほど示したように角括弧【[] 】の中身を空の状態で変数を作成します。
x = []
print(type(x))
print(x)
出力結果
<class 'list'>
[]
\(*\)演算子で0をかけることでも空リストにすることができます。
x = ['a', 'b', 'c', 'd']
z = x * 0
print(type(z))
print(z)
出力結果
<class 'list'>
[]
【list型】リストをから部分的に値を取得する方法
【list型】リストのそれぞれの要素の値を取得する方法を解説します。
インデックスを使った取得方法(N番目の値を取得)
それぞれの要素にはインデックス番号が割り振られていますので、各要素のインデックス番号を指定することで希望する要素の値を取得することができます。変数名の後に角括弧【[] 】をつけて要素のインデックス番号を記述することで取得できます。
x = ['a', 'b', 'c', 'd']
z = x[1]
print(z)
出力結果
b
「1」と指定して2番目の要素が取得されていますが、基本的にプロミングの場合インデックス番号は1からではなく0からカウントすることに注意してください。str型で一度学習しましたね。思い出してみましょう。
リスト内に含まれるリストの要素の値を取得したい場合は角括弧【[] 】を2つ利用します。基本的な考え方は同じですがリスト内にさらにリストがあるため1つ目の角括弧【[] 】でリスト要素のインデックスを指定し、2つ目の角括弧【[] 】をそのリスト内に含まれる要素のインデックスを指定します。
x = [['a', 'b', 'c', 'd'], ['e', 'f', 'g', 'h']]
y = x[1][2]
print(y)
出力結果
g
インデックスを使った最後の要素を取得する方法(-N番目の値を取得)
インデックス番号は終わりから指定することもできます。最後の要素を指定する場合は「−1」からカウントします。
x = ['a', 'b', 'c', 'd']
z = x[-1]
print(z)
出力結果
d
1番最後の値「d」が取得できていることが確認できます。
スライスを使った取得方法(N番目から、M番目未満の値を取得)
リストから部分的に複数の値を取得する場合はスライス機能を使います。スライス機能の使い方は変数の後ろにN番目から(始まりの値)、M番目未満(終わりの値の1つ後の値)を【 : 】でつなぎ角括弧【[] 】で囲みます。str型でN番目からM番目未満の文字列を取得した方法もこのスライス機能になります。
Note
スライス機能とは
説明するまでも無いかもしれませんが、言葉の通りデータを細かく切り分け(スライス)して部分的に取り出す方法です。後のセクションで解説しますがシーケンスと言われる複数のデータが並んだデータ型で利用することができる機能です。
x = ['a', 'b', 'c', 'd']
z = x[1:3]
print(z)
出力結果
['b', 'c']
リスト内にリスト要素を持ったリストでスライス機能を使う場合は下記のようになります。
x = [['a', 'b', 'c', 'd'], ['e', 'f', 'g', 'h']]
y = x[1][2:4]
print(y)
出力結果
['g', 'h']
スライスを使った取得方法(N番目から終わりまで、最初からM番目未満)
N番目から、もしくは、M番目未満を省略することで最初から、もしくは、終わりまでといった指定方法をとることができます。
始まりからM番目未満を取得する
x = ['a', 'b', 'c', 'd']
z = x[:3]
print(z)
出力結果
['a', 'b', 'c']
最初から3つ目の要素までのabcが取得されています。
N番目から終わりまで取得する
x = ['a', 'b', 'c', 'd']
z = x[1:]
print(z)
出力結果
['b', 'c', 'd']
2つ目から最後までの要素bcdが取得されています。
【list型】リストの変更と削除
【list型】リストの各要素の値の変更方法と要素の削除方法を解説します。
リスト要素の値を変更する
リストの要素の値を変更するには変更したい要素のインデックス番号を指定し新しい値を代入します。
x = ['a', 'b', 'c', 'd']
x[1] = 'z'
print(x)
出力結果
['a', 'z', 'c', 'd']
インデックス1の値「b」が新しく代入された「z」に変更されていることが確認できます。
リストの要素を削除する
リストの要素を削除するには削除したい要素のインデックス番号を指定しdelを使用します。
x = ['a', 'b', 'c', 'd']
del x[1]
print(x)
出力結果
['a', 'c', 'd']
インデックス番号1の要素「b」が削除されていることが確認できます。
【list型】リストの使いどころ
最後に今回学習した【list型】リストの使いどころを考えておきましょう。どのようなケースで利用できるのでしょうか。通常、利用するケースは「個別のラベリングが不要な値の集団」を扱う場合でしょう。
- 個別のラベリングが不要な値の集団
事例
次のデータベースをもとにいくつか目的別の事例を考えてみましょう。
参考データベース
参考データベースは、3クラスで各クラスの人数が40人のテストの点数データを集めたものとします。
| クラス名 | 性別 | 氏名 | 点数 |
|---|---|---|---|
| a | 男 | 山田 | 65 |
| b | 女 | 伊藤 | 78 |
| c | 女 | 井上 | 95 |
| ・ ・ ・ | ・ ・ ・ | ・ ・ ・ | ・ ・ ・ |
| a | 男 | 木下 | 83 |
| c | 男 | 川崎 | 91 |
目的例1:テストの平均点を求めたい
ケース1は「テストの平均点を求めたい」場合です。平均点を求めるだけであれば各人のテストの点数を合計しその合計数で割るだけで求めることができますのでデータベース内の点数データ(点数列データ)だけあれば良いことになります。つまり、ラベルが必要ありませんのでリストでデータを用意することができるといえます。
- ラベル不要、点数データだけがあれば良い = リストでOK
目的例2:赤点を取っている人の名前を知りたい
ケース2は「赤点をとっている人の名前を知りたい」場合です。この場合は、基準点を下回っている点数をピックアップした後、その点数を取った人の名前(氏名列データ)が必要となります。つまりラベル(名前)が必要ですのでリストだけでは対応することができないと言うことになります。
- ラベル(名前)必要 = リストNG
Q:クラス別の平均点は?
では「クラス別の平均点を求めたい」場合はどうでしょうか?
回答としては「どちらでもいける」になります。
- A:どちらでもいける
クラス別変数を作れば目的例1と同じ条件になる
クラス名がラベルとして必要になりそうな気がしますが、個人名と違い点数毎に個別のラベルとしてクラス名が必要なわけではありません。3クラス構成で各クラスの人数が40人といった場合であれば下記の様に変数を3つ用意することで対応することができます。
class_a = [95, 72, ・・・, 82]
class_b = [67, 86, ・・・, 94]
class_c = [86, 88, ・・・, 79]
もちろん、ラベルをクラス名にしても同じ結果を求める事はできます。最終的にどちらを選択すべきかはその後、変数をどのような処理に利用するのかや、処理速度などを考えながら選択していくようになります。
このようにどのデータ型を選択するかはある程度経験を必要とします。まずは、「個別のラベリングが不要な値の集団」を扱うときに利用できるデータ型と理解しておけばよいでしょう。
今日のdot
データ型がlist型の変数は、同時に複数の要素を扱うことができ、各要素の並びには順序がありインデックス番号が割り振られています。インデックス番号で変数内の各要素の値を取得できます。
x = [['a', 'b', 'c', 'd'], ['e', 'f', 'g', 'h']]
y = x[1][2:4]
print(y)
出力結果
['g', 'h']
【フリーランス向けの完全無料Pythonプログラミング講座】
dot blogではこの記事以外にも完全無料でフリーランス向けのPythonプログラミング講座を公開中です。フリーランスとして活躍し稼ぐための強力な武器となりますよ。

Python入門講座【無料のプログラミング学習講座】
最近特に注目度が高くなってきているプログラミング言語Python。転職、フリーランス、独立・起業を検討中、日々の業務が忙しい社会人等は今こそ身に付けておきたいスキルの1つ。初心者向けにやさしいプログラミング学習内容のPython入門講座を無料で公開。

